
I recently finished the course “Machine Learning for Business Professionals” from Google Cloud via Coursera. While the certificate normally costs about 40-50$, there is a limited time offer by Coursera where you get it for free. In this article, I will show you how to redeem this offer, what the course is about and if it is worth taking.
Today, all major cloud platforms offer sophisticated machine learning capabilities and training a simple classification model is just a few clicks away. While machine learning (ML) algorithms become increasingly powerful and ML frameworks are more and more mature, there are still significant barriers for introducing ML in many businesses. This course therefore does not focus on the technical aspects of ML but rather on the business challenges: Why should ML be introduced? Which use cases can benefit from ML models? How can ML be used responsibly as far as privacy and information security are concerned? And how can traditional businesses be transformed by leaning into ML?
How to Register for a Free Certificate
While most courses on Coursera can be audited for free, you usually do not get a certificate of completion. Such certificates can be added to your CV, your LinkedIn profile or your portfolio and show potential colleagues and employers that you actually finished your course.
For this particular course, Coursera is giving away free certificates due to the COVID-19 pandemic. You can register for your free certificate by visiting the following link: https://www.classcentral.com/course/machine-learning-business-professionals-13415
Then follow the “Go to class” link and log into your Coursera account. When you check out, the price for the certificate should be reduced to 0,00$.
Course Review
Free courses are always a good thing, but is this particular course really worth your time? In the following paragraphs, I will summarise my key insights.
The course is separated into four modules and is taught by different instructors from Google Cloud, all of which are very enjoyable to listen to.
Module 1: ML Use Cases and Chat Bots
The first module gives a general introduction to the business aspects of machine learning. It deals with characteristics of data sets, introduces terminology (Artificial Intelligence versus Machine Learning) and presents a few common use cases where machine learning can be used in typical business environments.
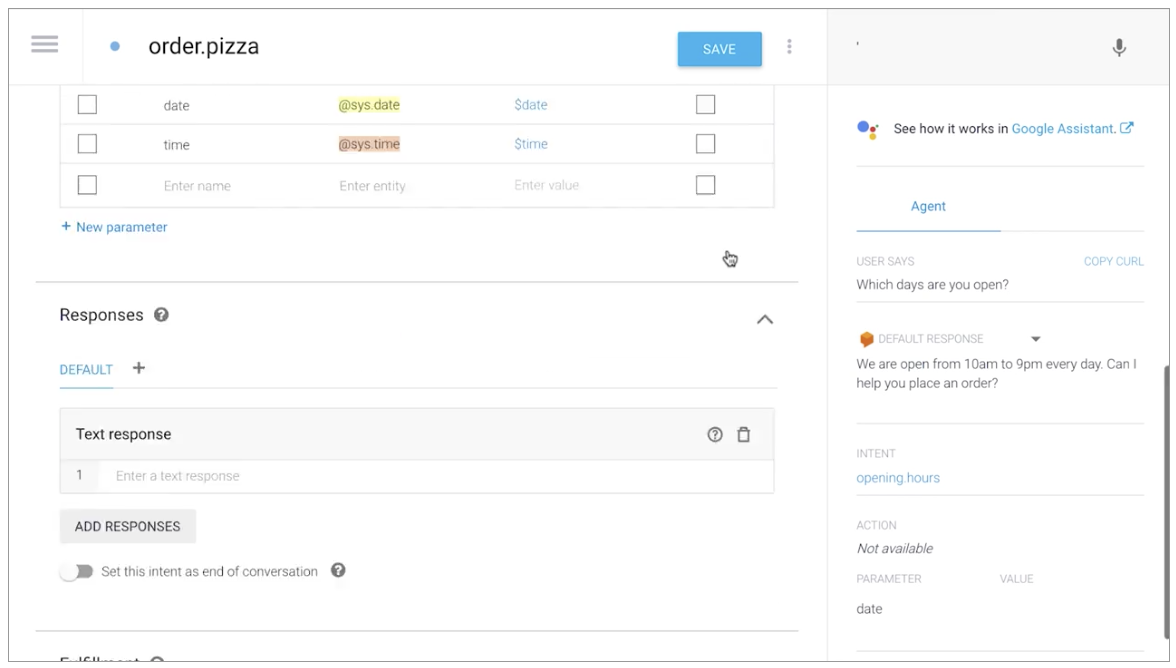
In the courses first of three hands-on labs, you are given access to a project on Google Cloud Platform (GCP) and build a chat bot using DialogFlow. In this example, your customer’s goal is to order a pizza of a certain size with one or more toppings at a certain date and time. You learn how to automatically identify parts of the sentences and ask for the remaining pieces of information. When I completed the assignment, this was a typical dialog with the chat bot:
Bot: Hello! How can I help you?
Me: Order a large pizza
Bot: What day do you want to pick up your pizza?
Me: Today
Bot: What time do you want to pick up your pizza?
Me: 4 pm
Bot: What toppings do you want on your pizza?
Me: Salami, jalapenos
Bot: We have placed your order for a large pizza with salami, hot peppers, for pickup on 2020-08-30 at 04:00 pm. See you then!
Module 2: Labeling Data and Biases
The whole module two is dedicated to a tremendously important aspect: data quality and biases. While this may not be obvious to everyone, the outcome of a ML model depends much more on the data quality than on the algorithm (often, simple algorithms such as decision trees even give superior results to fancy new algorithms that were tailored to a very specific problem).
While the technical aspects of this module (such as training/test set evaluation, statistical biases, …) were not new to me, I really enjoyed how they connected these concepts to practical examples in real-world use cases.
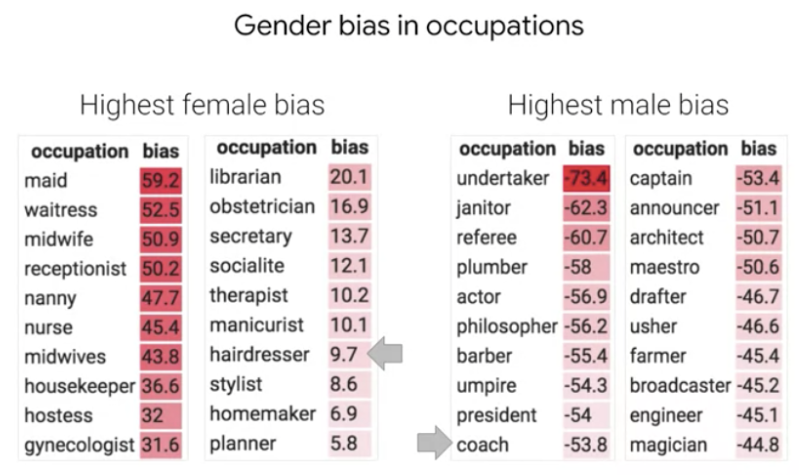
The second big concept of this module was biases. They pointed out some interesting cases where racial, sexual and other kinds of discriminations found their way into machine learning models – even though the ML engineers tried to avoid that. In a concrete example, they showed a model where a gender bias was introduced in a model although the model did not contain the person’s gender as an attribute. Instead, the bias was introduced because the model did contain the person’s occupation, and the model was able to learn that some occupations are statistically more typically associated with females (e.g., receptionist, housekeeper) while others are more typically male (e.g., janitor, plumber):
Module 3: Discovering ML Use Cases
This module felt the most relevant to me since I was already very familiar with the statistical and technical aspects but not the business aspects of ML. In this module, concrete use cases for ML in various business environments and their solutions were presented. I really appreciated how these use cases were not made up but related to real customers of the Google Cloud team.
One recurring theme of those use cases was personalisation. Today, customers expect personalised instead of mass-produced content. While in the past, a TV station would hire data analysts to optimise the TV schedule of a newly produced series (“we should send it at 9 pm because this was historically a good time for romantic comedies”), such recommendations must now be made thousands and million times per day, for each individual user (“should I recommend a new season of her favourite cartoon or this crime movie based on her past viewing history?”). Without ML, it is impossible to make such personalised recommendations.
Module 4: Data Strategies and ML Teams
The last module was the most business-focused one. They introduced the idea of a data strategy, where multiple teams and departments in a business need to collaborate to increase the available amount of high quality data sets. “Design your systems so that you will have more data next year” – this advice is definitely true and a good foundation for future ML endeavours.
The instructors also suggest relying on agile principles when introducing ML methodologies: do not aim for models with 100% accuracy and do not spend too much time on perfecting individual models. Most of the time, you get 80% of the business value with 20% of the effort (the famous Pareto principle). I find this to be true in so many areas of life that it is also true for ML.
Finally, the module finishes with the topic of ML teams. They argue that most companies do not actually need that much ML engineers (creating and maintaining the actual models) but rather a considerable number of data engineers (ingesting and transforming data) and data analysts (collecting, curating and exploring data).
Final Thoughts
In my opinion, it really helps if you already have a background on the technical aspects of ML (they are largely ignored or taken for granted in this course). However, due to the instructors’ real-world experience, there is very much one can learn about the business aspects of ML and I would highly recommend taking it. The lab exercises are rather sequential (“Do A, then do B, then click on export, …”) but you get a good overview of the most important functions in GCP.
Although there is a lot more to learn on the subject of ML, the course is a very good introduction that pretty much all engineering managers and CTOs would benefit from.